Update Study of Graded Comic Sale Prices20324
Pages:
1|
|
drloko private msg quote post Address this user | |
| I'm interested in updating a pricing study I did two years ago, I'm open to ideas for new directions. Previously I published a study of sales of graded comics. This looked at: (1) Predicting the current price of a graded book at one grade given recent sales at different grades (2) Price difference of books sold at the same grade in quick succession (later books sold for more) (3) Price difference of books sold at neighboring grades in quick succession Some ideas I had for next steps: (a) Examine the effects of the platform on sales price (eBay, MyComicShop, Heritage, ComicLink, etc.) (b) Quantify the price difference of books at the same grade between CGC and CBCS (c) Incorporate census data to improve price prediction Any other suggestions of price related topics to consider? |
||
| Post 1 • IP flag post | ||
 Collector Collector
|
consumetheliving private msg quote post Address this user | |
| To expand on the value gap between CGC and CBCS - if CGC values are inflated due to the boom is there a way to compare pre-boom CGC values (in grade) to current CBCS values to see if they are really selling for less? I have a feeling there will be more parity once CGC values level out some more. | ||
| Post 2 • IP flag post | ||
|
|
Rafel private msg quote post Address this user | |
| This sounds like your making your own price guide. Or are you trying to make a list (or guide) with two columns. One side CGC and the other side CBCS. | ||
| Post 3 • IP flag post | ||
 I'd like to say I still turned out alright, but that would be a lie. I'd like to say I still turned out alright, but that would be a lie.
|
flanders private msg quote post Address this user | |
| A big effect on price, which you haven't included, is the actual appearance of the book for the given grade. A well centered book with vibrant colors and no miswrap in an 8.0, or any grade, should always sell for more than a book in the same grade with a miswrap, poor centering and duller colors. Current guides can only take you so far. |
||
| Post 4 • IP flag post | ||
 Staple topics, nice. Staple topics, nice.
|
makahuka private msg quote post Address this user | |
| Interesting. | ||
| Post 5 • IP flag post | ||
 Whenever you have a monkey riding a horse, I'm in. Whenever you have a monkey riding a horse, I'm in.
|
Tom74152 private msg quote post Address this user | |
| Following | ||
| Post 6 • IP flag post | ||
|
|
drloko private msg quote post Address this user | |
Quote:Originally Posted by Rafel Not an independent price guide. For example, if there are recent sales of a book at 8.0 and 8.5, what is the current price at 9.4? If there are no recent sales at 9.4, you need to estimate the price based on the recent sales at 8.0 and 8.5. |
||
| Post 7 • IP flag post | ||
|
|
Rafel private msg quote post Address this user | |
Quote:Originally Posted by drloko What about 9.6 and up to 10's, same thing? |
||
| Post 8 • IP flag post | ||
 Collector Collector
|
poka private msg quote post Address this user | |
| @drloko Why are you doing this / for what purpose? Personally I see the biggest price movements for books are whether sold on auction or buy it now - especially for less desired books |
||
| Post 9 • IP flag post | ||
 " . " " . "
|
Davethebrave private msg quote post Address this user | |
| To calc implied values you need to focus on census data. That is critical as grade distributions vary. For thinly traded books you will need to accept greater variance - it will be more difficult to accurately predict. Reasons are twofold but both have to do with liquidity: 1) seller desperation - a desperate seller will have a greater impact on a price result for a thinly traded (rare) book than a book with high trading volume and 2) buyer desperation - a desperate buyer may pay “off market” prices for a book with limited availability. For highly traded books if you have the right census data and model, you should rather easily plug gaps. The thing is that you won’t need to as often… because they are regularly traded. So gets back to purpose. You won’t get much accuracy for thinly traded/rare books and you won’t need an implied model for most heavily traded books. |
||
| Post 10 • IP flag post | ||
 Masculinity takes a holiday. Masculinity takes a holiday.
|
EbayMafia private msg quote post Address this user | |
Quote:Originally Posted by Davethebrave Would it be helpful for prediction purposes if one could gather more information about the reasons behind the thin trade volume? I.E. understanding if it is a supply issue or a lack of demand issue? I know that small numbers become less consistent, but I wonder if one could put together a set of data points (MCS want list numbers and annual sales volume vs. current quantity available on specific platforms, asking prices vs. most recent sales prices, Ebay page views/watchers, etc. that would help to narrow down a more likely range? |
||
| Post 11 • IP flag post | ||
|
|
drloko private msg quote post Address this user | |
Quote:Originally Posted by poka This is part of a larger system that identifies fraudulent bidding activity at auction. It also identifies market inefficiencies. |
||
| Post 12 • IP flag post | ||
|
|
drloko private msg quote post Address this user | |
Quote:Originally Posted by EbayMafia Demand side data would likely improve the performance considerably, especially in conjunction with supply side (census data). |
||
| Post 13 • IP flag post | ||
|
|
drloko private msg quote post Address this user | |
Quote:Originally Posted by Davethebrave The accuracy of the model is within the tolerance of the ordinary transaction variance. Although there are exceptions at the extreme volumes, the majority of sales are outside of the drift window of the price. |
||
| Post 14 • IP flag post | ||
|
" . "
|
Davethebrave private msg quote post Address this user | |
Quote:Originally Posted by EbayMafia Definitely helps - but it will still have a much wider range than an actively traded book. I think arming oneself with that info can help with negotiation, to a degree. To have a fair market value you need an active market. The less of an active market, the less you can confidently point to a “market” value… If I am a seller of a book with no clear FMV then I am going to list it very high (how high is “very high” can be informed by an analysis but will necessarily be uncertain). I’d then allow a wide range of offers. Alternatively, I’d put it in an auction with the right buyer demographic/sufficient exposure. Generally, I’d assume it will take more time to sell at its highest potential price. Real estate is often priced this way. Homes with easy comps and a highly transacted market/price range can he priced for faster sale. Easier to set a market clearing price. Easier to appraise (or easier to get appraisals that are similar). At higher price points and/or properties with unique attributes, a typical strategy is to price high and walk it down over time… appraisals are mor difficult and you’ll end up with much wider ranges of estimates. Even if more data is gathered you will not have the same potential range of outcomes… |
||
| Post 15 • IP flag post | ||
|
Masculinity takes a holiday.
|
EbayMafia private msg quote post Address this user | |
Quote:Originally Posted by drloko Census data would be quick and easy, but I don't think it has a direct correlation with how many copies will actually be available to buy, either immediately or in the future. I think the supply side information would have to be more complex than just census data in order to be usefully predictive. I think you would have to look at available-for-sale across 4-5 consistent platforms and use that information in an equation that would probably include census data. Probably would also need tranches of VG and below, Fine-Very Fine, and Above Very Fine. |
||
| Post 16 • IP flag post | ||
|
" . "
|
Davethebrave private msg quote post Address this user | |
Quote:Originally Posted by drloko Goes to the original point - regularly transacted books don’t really need a model to predict (easy to interpolate between grades). Books rarely transacted and/or scarce overall - you won’t get much predictive value out of the model. Edit: for platform impact on price I’d like to see that analysis… I suspect it will be hard to draw conclusions with much confidence between the major platforms when looking at the same format (auction vs auction, BIN vs BIN, etc). |
||
| Post 17 • IP flag post | ||
 Collector Collector
|
Neutrons private msg quote post Address this user | |
| Do you have a preview of your study? | ||
| Post 18 • IP flag post | ||
|
|
drloko private msg quote post Address this user | |
Quote:Originally Posted by Neutrons The previous study is available for preprint at: https://www.scienceopen.com/hosted-document?doi=10.14293/S2199-1006.1.SOR-.PPIZWRJ.v1 |
||
| Post 19 • IP flag post | ||
|
" . "
|
Davethebrave private msg quote post Address this user | |
Quote:Originally Posted by drloko Great read and well-constructed analysis. |
||
| Post 20 • IP flag post | ||
 I'm not a plagiarist. I'm also not illiterate. I'm not a plagiarist. I'm also not illiterate.
|
drmccoy74 private msg quote post Address this user | |
Quote:Originally Posted by Davethebravecorrect 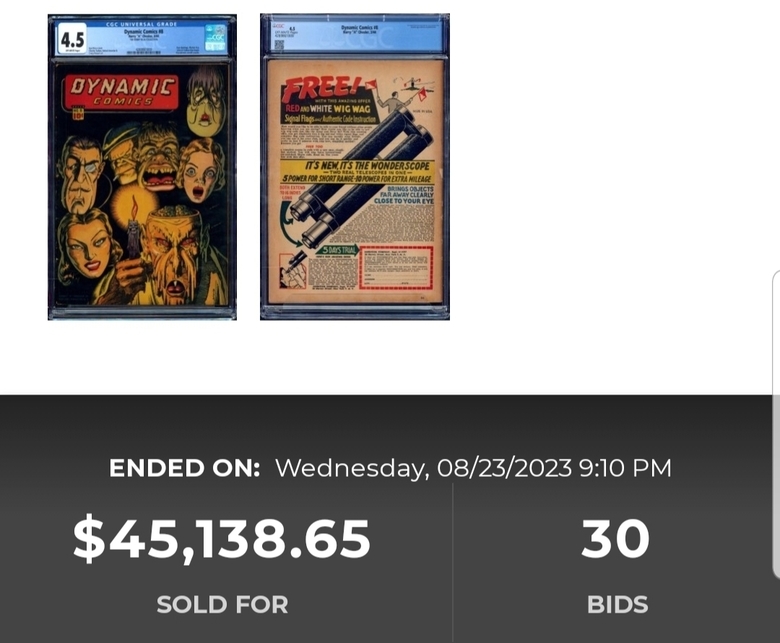 |
||
| Post 21 • IP flag post | ||
|
" . "
|
Davethebrave private msg quote post Address this user | |
Quote:Originally Posted by EbayMafia Census data should be relevant in helping to predict pricing steps, especially non-incremental steps (say from a mid grade to high grade) because the distributions can vary significantly. Some books have a relatively normal distribution to grades; some have significant skew. Buyers should be aware of the relative scarcity differences since the data is readily available and it should factor into the pricing-grade relationship. |
||
| Post 22 • IP flag post | ||
|
" . "
|
Davethebrave private msg quote post Address this user | |
| This is outside the scope of OP’s question but I’d love to see a combination of the following analyses and sampling: 1) CBCS vs CGC prices at same grade 2) Grade change from a resubmission of a CBCS book into CGC and vice versa The dominant view on this forum is that CBCS grades lower but CGC at same grade prices higher. If both of the above are generally true for higher priced books (to offset trxn costs), there is a very real arbitrage opportunity. |
||
| Post 23 • IP flag post | ||
 Collector Collector
|
TommyJasmin private msg quote post Address this user | |
Quote:Originally Posted by Davethebrave @Davethebrave - great commentary on the thread. It's nice to see someone tout the value of census data. I see too many forum posts discount the usefulness of census data, which I talk about in detail here. As far as your two requests, Nostomania has always done #1. It boggles my mind why the big comic pricing sites do not differentiate. #2 is just too much effort. Sure, it happens, and it's really cool to see the data. But to expect people to reguarly submit a significant quantity of books to CBCS, and when they come back, crack them open and send them to CGC? And for completeness and fairness even PGX? Just too much time and effort. My site can already tell you the answer. With less confidence of course Neat thread. Nice work @drloko. Oh, one more thing. In this thread "model" gets tossed around like it's some static thing. There are crap models and great models. The most popular sites have pretty crap models. E.g. Average of all sales at a given grade. if no sales at a grade, then "no FMV". That is embarrassing. On the other hand, a decent model can predict value in the absence of sales. Name a book and I'll show you. Here, random Golden Age horror: 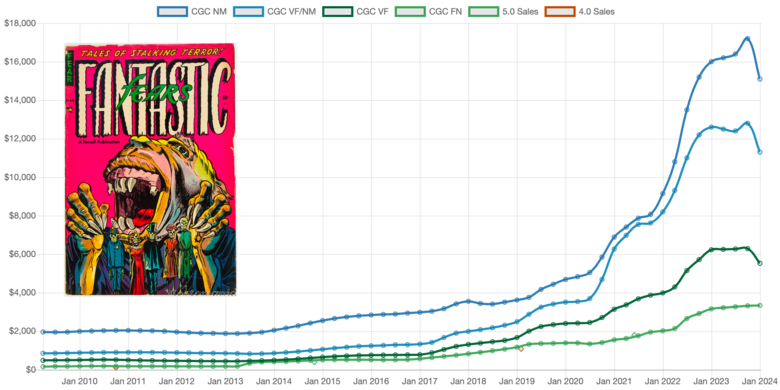 So few sales, period. So how do I know the trend? I'll just say this - a good data model is not a trivial effort. |
||
| Post 24 • IP flag post | ||
Pages:
1This topic is archived. Start new topic?